房地产自动定价(一)
一切的开始
这房地产自动定价呢,其实是个项目。而这个项目的故事则说来话长了。记得大概是去年5月接了这个项目,后来浑浑噩噩地做了一段时间,最后似乎是因为技术上不过关就放弃了治疗(十分不提倡这种学术精神!)。
但这件事情可没有这么简单。。。
很快,大概六月份我们就要结题了。

相比于混过最后这段日子,我觉得,还是冲一冲吧!
这个系列博文将会记录我冲击路上所将经历的坎坷。
爬虫部分
在数据挖掘之前肯定需要做一个数据集,不同于以往,这次我打算用scrapy框架来爬取房地产网站的有关数据。
首先,我们来用scrapy来自动生成一个基础框架:
(HousingEvaluation) E:\code\python_code\HousingEvaluation>scrapy startproject HousingDataScrawler
Fatal error in launcher: Unable to create process using '"d:\bld\scrapy_1584555977003\_h_env\python.exe" "D:\Program Files\anaconda\envs\HousingEvaluation\Scripts
\scrapy.exe" startproject HousingDataScrawler': ???????????
哎呀!报错了!在网上查了一圈之后发现原来使需要用以下命令来执行,感觉错的好冤枉!o(╥﹏╥)o:
python -m scrapy startproject xxx
这里可以看一下生成之后的程序结构。
然后我们选好我们希望爬取房源信息的网站。这里选的是链家。
| 房屋户型 | 所在楼层 | 建筑面积 | 户型结构 | 套内面积 | 建筑类型 | 房屋朝向 |
|---|---|---|---|---|---|---|
| 2室1厅1厨1卫 | 中楼层(共4层) | 54.14㎡ | 平层 | 37.7㎡ | 板楼 | 南 北 |
| 建成年代 | 装修情况 | 建筑结构 | 供暖方式 | 梯户比例 | 产权年限 | 配备电梯 |
|---|---|---|---|---|---|---|
| 1990 | 精装 | 混合结构 | 集中供暖 | 一梯两户 | 70年 | 无 |
之后我们点开网站,发现每个房源都会有这么一系列的信息,而这些信息中大部分都是有用的。这里我们选取**房屋户型(house_type)、所在楼层(house_floor)、套内面积(house_area)、建筑类型(house_type)、房屋朝向(house_towards)、建成年代(completion_time)、装修情况(house_finish)、梯户比例(elevator_ratio)、配备电梯(have_elevator)以及页面上的房屋标题(house_title)、房屋价格(house_price)、交易时间(trading_date)**进行爬取。
以下是HouseDataItem的构成。
class HouseDataItem(scrapy.Item):
house_title = scrapy.Field()
house_floor = scrapy.Field()
house_price = scrapy.Field()
house_type = scrapy.Field()
house_finish = scrapy.Field()
house_area = scrapy.Field()
house_towards = scrapy.Field()
have_elevator = scrapy.Field()
elevator_ratio = scrapy.Field()
completion_time = scrapy.Field()
trading_date = scrapy.Field()
接下来就是痛苦的解析环节了,因为要解析的东西实在太多,就不做解释了,直接上代码。
def parse(self, response):
houseDataItem = HouseDataItem()
houseDataItem['house_title'] = response.xpath('/html/body/div[4]/div/text()').extract()[0].strip()
houseDataItem['house_price'] = \
response.xpath('/html/body/section[1]/div[2]/div[2]/div[1]/span/i/text()').extract()[0] + \
response.xpath('/html/body/section[1]/div[2]/div[2]/div[1]/span/text()').extract()[0].strip()
date_in_text = response.xpath('/html/body/div[4]/div/span/text()').extract()[0].strip()
if date_in_text.split(" ")[1] == "成交":
houseDataItem['trading_date'] = date_in_text.split(" ")[0].strip()
houseDataItem['house_floor'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[2]/text()').extract()[0].strip()
houseDataItem['house_type'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[6]/text()').extract()[0].strip()
houseDataItem['house_finish'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[8]/text()').extract()[0].strip()
houseDataItem['house_area'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[3]/text()').extract()[0].strip()
houseDataItem['house_towards'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[7]/text()').extract()[0].strip()
houseDataItem['have_elevator'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[14]/text()').extract()[0].strip()
houseDataItem['elevator_ratio'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[12]/text()').extract()[0].strip()
houseDataItem['completion_time'] = \
response.xpath('//*[@id="introduction"]/div[1]/div[1]/div[2]/ul/li[8]/text()').extract()[0].strip()
yield houseDataItem
啊哈,总算搞定啦!这样之前准备好的160000条链接就可以被逐个爬取啦!!!
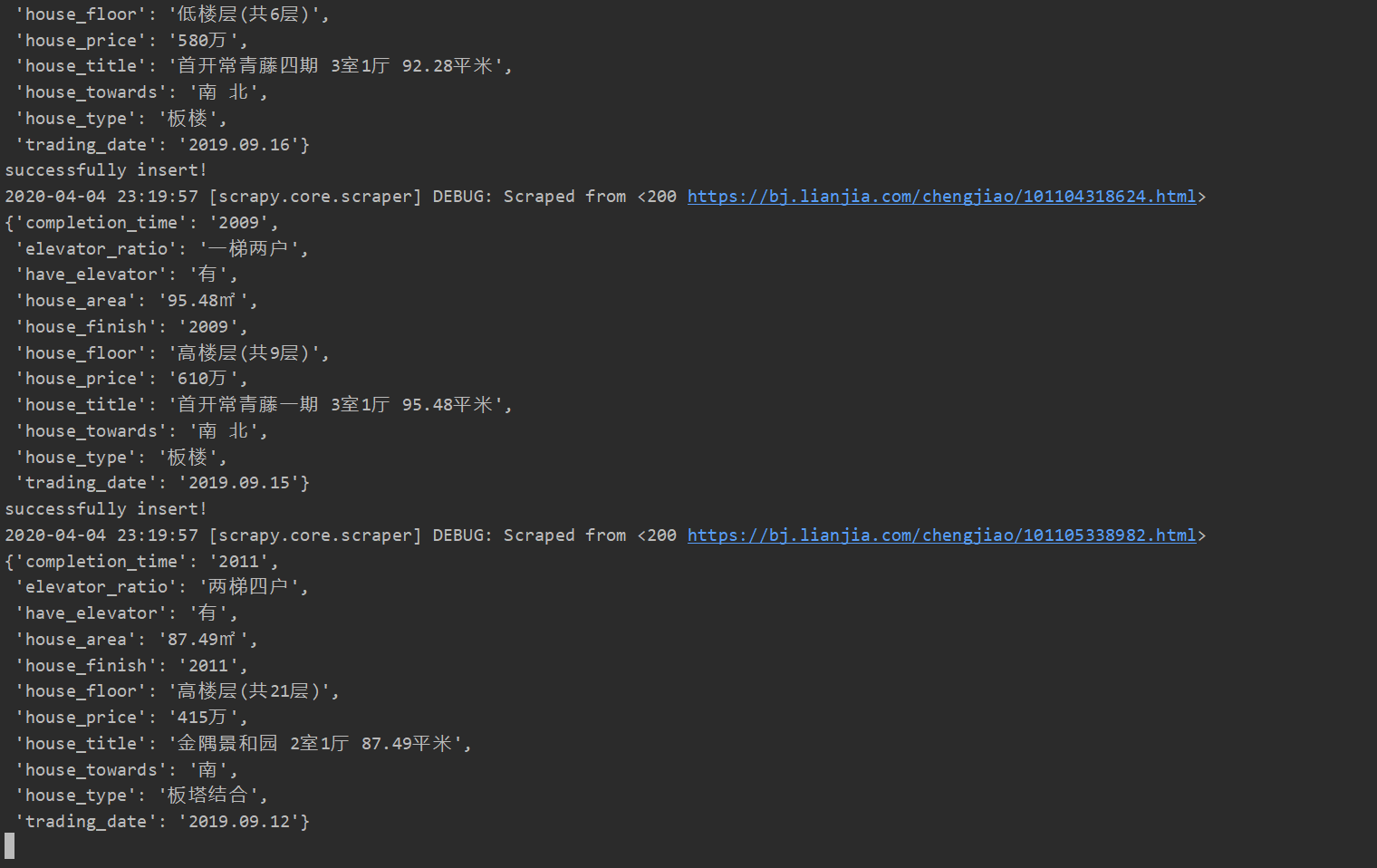
速度还是很快的,估计十二点左右就可以全整到数据库里啦!是异常开心了O(∩_∩)O哈哈~
那么,今天就这样啦,明天准备把这爬到的原始数据格式化了~~ 希望能坚持下去啊!
git仓库链接:https://github.com/AIINIRII/HousingEvaluation/