房地产自动定价(三)
数据的爬取和预处理都结束了。接下来,我打算利用简单的BP网络模型去对这些数据进行一个简单的拟合。这里,我用到了TensorFlow的2.1.0版本。
输入输出选择
因为打算先跑跑BP神经网络看看效果,所以输入输出先不选的过于复杂。
INPUT: place_id, house_type, house_area, house_towards
OUTPUT: house_price
这四个输入数据分别是
- 地区的id(我已经自行为每个地区进行了编号,例如安定门:1)
- 房屋的类型(我也已编了号,例如板楼:0)
- 房屋的面积(单位为平方米)
- 房屋的朝向(我也编了号,例如南:0)
而输出数据为房屋的成交价格(单位万元)
数据处理
将数据集整理并扁平化之后,输入数据X_data变成了一个大小为(150731,310)的数据集,其中310=4+8+297+1;我采用了one_hot的编码方式将房屋的朝向、类型以及面积均变成了一个个列向量,在这之后我把他们合并到一起,其中4代表的是4种房屋类型,8代表的是8种朝向,297代表的是297种地区,这个列向量的最后一个元素是房屋的面积。
开始模型搭建
def model_build(n):
# shape of X_train: (120584, 310), shape of X_test: (30147, 310)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, input_shape=(n,)),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(64),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer=Adam(learning_rate=0.1), loss='mse', metrics=['mae'])
return model
这里采用了两层RELU去进行拟合。
模型的初尝试
def scheduler(epoch):
# 每隔100个epoch,学习率减小为原来的1/3
if epoch % 100 == 0 and epoch != 0:
lr = tf.keras.backend.get_value(model.optimizer.lr)
tf.keras.backend.set_value(model.optimizer.lr, lr * 0.3)
print("lr changed to {}".format(lr * 0.3))
return tf.keras.backend.get_value(model.optimizer.lr)
if __name__ == '__main__':
# print(f"X's shape: {X.shape}, Y's shape: {Y.shape}")
EPOCHS = 200
X_train, Y_train, X_test, Y_test = load_div_dataset() # load data set
# data normalization
mean = X_train.mean(axis=0)
std = X_train.std(axis=0)
X_train -= mean
X_train /= std
X_test -= mean
X_test /= std
reduce_lr = LearningRateScheduler(scheduler)
model = model_build(X_train.shape[1]) # build model
model.summary() # print the structure of model
# training begin
history = model.fit(X_train, Y_train, epochs=EPOCHS, batch_size=128, validation_split=0.2,
verbose=2, callbacks=[reduce_lr])
# save the model
model.save("model\\model_weight.model", overwrite=True)
# evaluate model
print("train data: ", end="")
model.evaluate(X_train, Y_train, verbose=2)
print("test data: ", end="")
model.evaluate(X_test, Y_test, verbose=2)
第一次结果
不得不说,看到了第一次的结果之后我是崩溃的。

为什么loss和mae这么高,我明明已经。很努力了啊!
train data: 120584/120584 - 7s - loss: 105549.9276 - mae: 218.9371
test data: 30147/30147 - 2s - loss: 105881.7860 - mae: 217.9669
你可能对mae不太了解??
大概就是说,对每一笔预测,都会有大概218万元的误差。。。。
那还预测个锤子啊hhh
一些改良
休息了一会儿平静了一下,我发现,这个结果至少说明了我们的代码能跑,至少说明了没有过拟合O(∩_∩)O。
分析之后发现,这么离谱的结果反映的是bias偏大。那么有几个解决的措施:
- 加训练数据
- 加深网络
- 加长训练时间
- 用更好的优化方法
- 换个神经网络结构
我发现。。好像除了优化神经网络我没什么可以做的~
于是,我回头去把网络加深了一层。。但突然意识到!诶,我用的是one_hot那么之前的那段normalization是不是有问题!
# data normalization
mean = X_train.mean(axis=0)
std = X_train.std(axis=0)
X_train -= mean
X_train /= std
X_test -= mean
X_test /= std
这样做法,我的std必是0啊,那肯定会出问题的!!
所以,经过深思熟虑,我把我的normalization part改成了下面这样:
# data normalization
mean_area = X_train[:, -1].mean(axis=0)
std_area = X_train[:, -1].std(axis=0)
print(f"X_train_area_data: {X_train[:, -1]}")
X_train[:, -1] -= mean_area
X_train[:, -1] /= std_area
X_test[:, -1] -= mean_area
X_test[:, -1] /= std_area
print(f"After normalization: X_train_area_data: {X_train[:, -1]}")
这么改完之后,我又顺便把我的网络加深了一层:
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, input_shape=(n,)),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(128),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dense(1)
])
果不其然,这么一改之后,在epoch=200的时候mae就下降到了100左右:
train data: 120584/120584 - 7s - loss: 21548.4162 - mae: 102.1043
test data: 30147/30147 - 2s - loss: 24309.7117 - mae: 106.6957
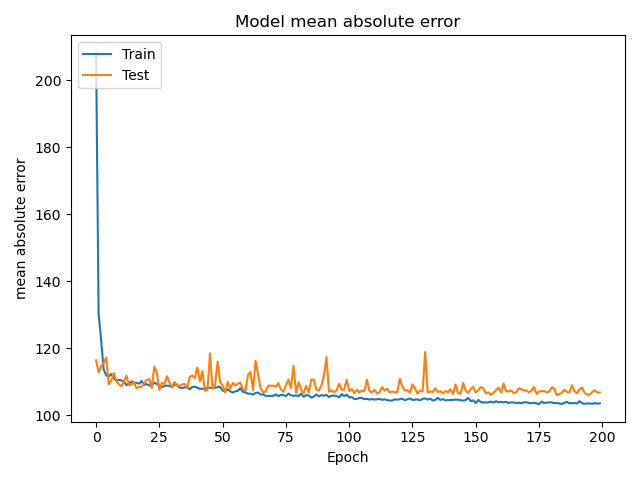
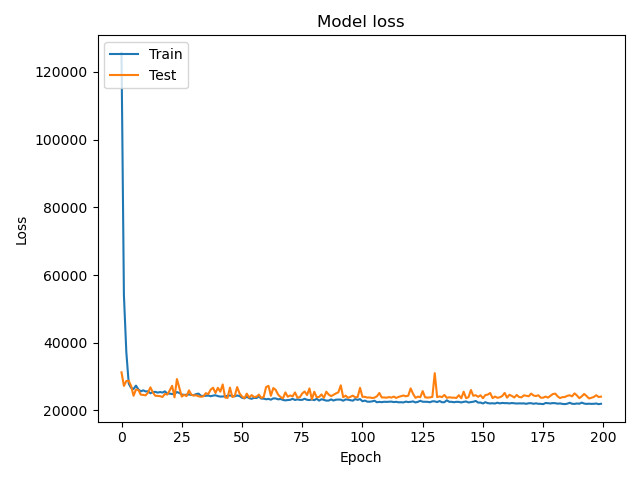
虽然依旧很高,但是比起之前来说好很多了呢

今天暂时先这样吧,先睡一觉,想想是不是能有什么好方法ε=(´ο`*)))唉
git仓库链接:https://github.com/AIINIRII/HousingEvaluation/